Puzzling in J - Expelled¶
2020-11-29
Introduction¶
I like puzzles. I also like code golf, which is really just puzzle-solving in as few bytes as possible.
Jane Street is a private trading firm in New York City. Every month, they post a new puzzle and invite people to solve it. May's puzzle is called Expelled. (Author's note: this was a lot more relevant when I wrote this back in May.)
Puzzle¶
Here's the puzzle:
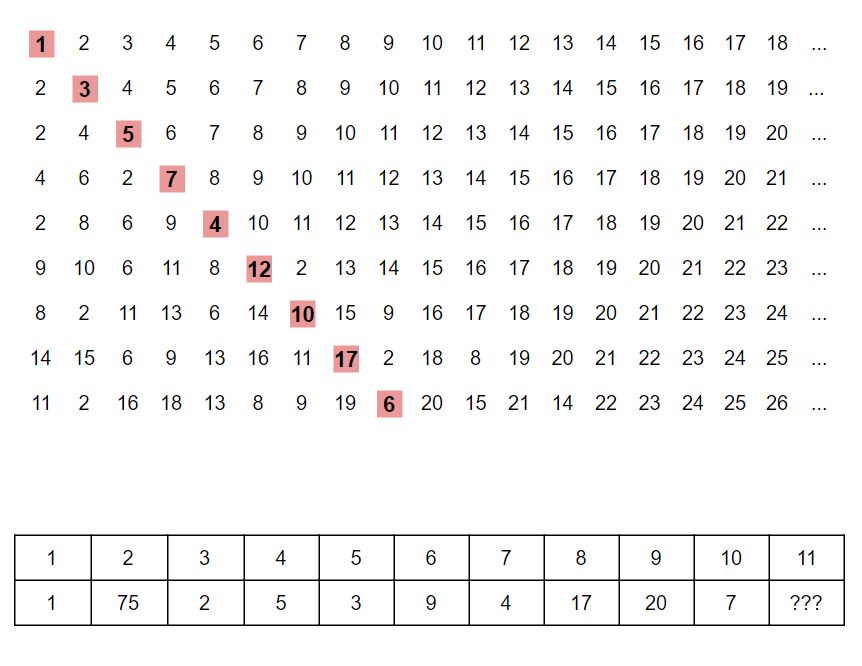
The goal is to figure out the value of ??? for 11.
Solution¶
Let the red highlighted number be the "diagonal number" for a row.
For a given row x_n, x_n+1 is assembled by collecting the values around the diagonal number, alternating between the left and right value, and moving further away from the diagonal number until it's impossible to collect any more values from the left side. The new diagonal number is the index of the current diagonal number plus one (by definition). For example:
4 6 2 [7] 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ...7 is our starting number, so we begin with 2, then 8, then continue alternating back and forth (6, 9, 4, 10). After that, we can fill in the rest of the numbers in sequence (11, 12, 13, etc.) Thus, the new row is:
2 8 6 9 [4] 10 11 12 13 14 15 16 17 18 19 20 21 22 ...The table at the bottom of the puzzle (with 11 and ???) is a table of values and indexes along the diagonal. So if we were to take the values along the diagonal as an array, then the value 5 would occur at (one-based) index 3. 7 occurs right after at index 4.
11 is at index 416.
Python solution¶
#!/usr/bin/env python3
def zigzag(index, lst):
new_list = []
# For a given row, the next row alternates between decreasing leftwards indices and increasing rightwards indices,
# until the leftmost indices hit the beginning of the array.
for i in range(1, index+1):
new_list.append(lst[index-i])
new_list.append(lst[index+i])
# Extend with the remainder of the list, which increases normally.
new_list.extend(lst[2*index+1:])
return new_list
def main():
# Initial sequence.
x_prev = [x for x in range(1,10000)]
x_final = []
x_final.append(x_prev)
for start in range(0, 500):
# Compute the next row from the previous row.
x_n = zigzag(start, x_prev)
x_final.append(x_n)
x_prev = x_n
diags = [x_final[i][i] for i in range(0, 500)]
print(' '.join("{:3}".format(str(x)) for x in range(1, 12)))
print(' '.join("{:3}".format(str(diags.index(x)+1)) for x in range(1, 12)))
if __name__ == "__main__":
main()
(default) david@curie ~/devel/scratch/janestreet-puzzles/expelled
% ./main.py
1 2 3 4 5 6 7 8 9 10 11
1 75 2 5 3 9 4 17 20 7 416But can it be smaller?¶
The Python solution is fine. It's clean and straightforward. But it's awfully... full of characters. What if I wanted to fit this in an original-style Tweet? What if I had to hand-write this code?
Enter J.
What is J?¶
J is an array-based programming language à la APL, except it doesn't require a special Selectric golf ball to type. In fact, J is developed in part by Kenneth Iverson, who is also the creator of APL. Like it says on the tin, array-based programming languages operate primarily on arrays. It's particularly well-suited for things like data processing or working with tabular data.
If you want an absolutely mind-blowing example of what you can do with APL and array-based languages in general, I recommend this YouTube video that implements Conway's Game of Life in one line of APL.
Why J?¶
There are a few reasons why I enjoy golfing in J.
J is expressive¶
It turns out you can express a lot of problems as arrays and operations on arrays. It takes some adjustment at first, but I was surprised how many problems are succinctly and effectively expressed with an array-based language.
J is terse¶
This should go without saying, but J is incredibly terse if you want it to be, which naturally lends itself well to golf. One of the neat features of the language is its support for tacit programming, which involves writing code without explicitly passing arguments. (Also called point-free style, stack-based languages like Forth and Factor are famous for this.) In J, verbs (functions) have both monadic and dyadic forms, which are forms that take either one or two arguments. For example, to write a sum of squares function, you could do:
sumsq =: +/ @: *: 1 2 3 4
sumsq 1 2 3 4
30+/ zips + with an array, *: is the square operator, and @: composes a monad and a dyad.
Notice we never explicitly declare arguments for the verbs. This makes it easy to express a lot in a small amount of characters.
J is cool¶
J is just a cool language. Array-based programming isn't a paradigm I encounter every day, so it's nice to use a tool that makes me think about solving problems in different ways. J requires a shift in thinking about how to write code, but once you make that shift it becomes so much easier to do things the "J way".
Brief J primer¶
Although this post is meant to primarily show what you can do with J, I'm aware that probably a healthy majority of people haven't used the language before. I don't want this to be a J tutorial, but I also want it to make some sense to the unitiated. To that end, here's a quick primer with all of the stuff you need to know for this post.
Conjunction junction, what's your function? Or, terminology.¶
J borrows terminology from linguistics. J code is made up of nouns, verbs, adverbs, and conjunctions.
A verb is a function. + is a verb, as is # and $.
A noun is some kind of value, e.g. an atom or an array. Verbs operate on nouns.
Adverbs and conjunctions modify other parts of speech, usually verbs.
The J Glossary defines these terms and many more.
Evaluation¶
J is evaluated from right to left.
Monads and dyads¶
Verbs are either monadic or dyadic. Not monadic in the Haskell sense, but in the musical sense. A monadic verb takes one argument and a dyadic verb takes two.
Rank¶
J, and other array languages, has the concept of rank. I encourage you to consult the fantastic J documentation, but I'll attempt to explain it here: rank is basically dimensionality. Noun rank is the dimensionality of the array, which is straightforward enough. Verb rank is more interesting, though. *, for example, operates on Rank 0 0, meaning individual atoms of arrays. This is why multiplying two arrays operates pairwise on atoms of the array. You can use the " conjunction to specify a verb's rank if you need to. You can also use " to declare a rank when declaring a verb.
There's a lot more to rank than that, but this explanation should suffice for this exercise.
J solution from the bottom up¶
Okay. Let's begin assembling the J solution.
Coming up with a solution in J wasn't as simple as just wholesale converting the Python program. Because the paradigms used by both languages are so different, you can't easily just translate the Python. But that wouldn't be fun anyway!
I've noticed that J makes it easier for me to think about my programs in a bottom-up fashion. For this puzzle, I first looked at how to get the first part of the next row from the current row. So, given a row like:
4 6 2 [7] 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ...and the index of the red number on the diagonal, 3, we want a function that will return the first part of the next row. To do that, though, we'll need a function to help us index into the current row to retrieve the values we want.
Don't be so negative¶
Recall that to assemble the next row up to the diagonal, you need to take values from the current row by alternating between leftward and rightward values around the diagonal number. For the row above, the indexes relative to 7 are -1 1 -2 2 -3 3. We want a function that takes a number and generates a sequential array of pairs that alternate between positive and negative. That shouldn't be too hard!
Much like a thunderstorm, let's generate some positives and negatives. We can use the dyadic shape verb $ to create arrays with repeated values:
4 $ _1 1
_1 1 _1 1
5 $ _1 1
_1 1 _1 1 _1
6 $ _1 1
_1 1 _1 1 _1 1(Syntax note: in J, negative signs are indicated with an underscore).
Let's define a helper function, double, to make things a bit easier to parse visually:
double =: 2&*& is a conjunction, called bond, that turns dyads into monads by partial application. So this just multiplies the input by two.
Now we can write f1:
f1 =: $ & _1 1 & double
f1 3
_1 1 _1 1 _1 1f1 doubles the input, then copies _1 1 that number of times.
We're getting closer! We just need each pair to get sequentially larger. As ever, J encourages us to think in terms of arrays. How can we use another array to turn _1 1 _1 1 _1 1 into _1 1 _2 2 _3 3?
f2 =: 2 # 1+i.
f2 3
1 1 2 2 3 3#, or copy, copies each value of y x times. Now we can simply multiply the two arrays, because J multiplication, *, between two arrays is performed on individual elements.
f3 =: f2 * f1
f3 3
_1 1 _2 2 _3 3Cool! Now we have a function, f3 x, that takes a number and outputs a sequential array of pairs that alternate between positive and negative.
Row, row, row your... row¶
So now we can generate an array that we should be able to use to index into the current row to get the values for the next row. The problem is, though, we have an entire row array, but our indexes are relative to the diagonal number. We'll need to offset.
Let's pick a row that isn't the first one. It makes it a bit easier to see what's happening with the indexing. Let's define x_3:
x_3 =: 4 6 2 , 7+i.30
x_3
4 6 2 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36Dyadic append , joins two arrays, and monadic integers i. generates sequences. 7+ offsets that sequence by 7, which gives us our fourth row, and lets us avoid typing out a long array of numbers.
We'll also want to start keeping track of the index of the current diagonal number, which is necessary to compute index offsets. For the fourth row, x_3, that's 3. Let's call it start:
start =: 3Now we're ready to write this function. First, let's convert our relative index offsets to absolute ones:
start + (f3 start)For x_3, this would give 2 4 1 5 0 6. Then we use from { to index into the row. It will be applied for each atom of the left argument (using parentheses to get the correct evaluation order):
g1 =: 4 : '((x + (f3 x)) { y)'
start g1 x_3
2 8 6 9 4 10If we consult the original puzzle image, we can see that this is indeed part of the next row!
You might notice something different about the definition of g1: it isn't tacit. Indeed, I was having trouble coming up with the tacit definition myself, so I defined the function explicitly. The 4 given before the verb is known as a type in J, which declares the verb as an explicit dyad. "Learning J" Chapter 12 goes into more detail about types. Later on we'll get the J interpreter to automatically convert this into a tacit form more appropriate for shaving off characters for golf.
Now we have to fill in the other side:
g2 =: 4 : '(1 + x * 2) }. y'
start g2 x_3
11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36We use drop }. to drop the first part of the row. 1 + start * 2 will give us the correct offset.
Finally, we can concatenate those two arrays:
g3 =: g1 , g2
start g3 x_3
2 8 6 9 4 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36And we have our next row! We sould verify that this works with the first row:
x_0 =: 1+i.30
0 g3 x_0
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30Cool!
Putting it all together (almost)¶
We can get the subsequent row from a given row, now we just need to start with the first row and iterate.
I'll admit that this was much harder for me than I had assumed. Because g3 returns the next row, what we really need is to be able to do something like:
... 2 g3 (1 g3 (0 g3 x_0))Typically, looping in J is either done implicitly with normal function application, or with the help of some adverbs that allow you to do things like apply a verb to successive suffixes of an array. I tried everything I could think of, but carrying the newly-returned row through to the next function invocation each time proved to be difficult for me.
So I reached out on Stack Overflow, and received some kindly help from someone more knowledgable about J than me. Because I didn't provide some of my function definitions to save time and space, I accidentally gave the answerer some incorrect assumptions, and the answer ended up not working. I was able to adapt the general strategy, though, and come up with a solution that worked. Of course, there's always more than one way to do it (TIMTOWTDI is familiar to any Perl fans out there), and perhaps there's a shorter solution, but this is what I have.
Much like moving, the solution involves boxes.
Boxes in J are an abstraction that lets you treat a potentially heterogeneous group of things as a group of one thing. From "Learning J", chapter 2 §6:
The main purpose of an array of boxes is to assemble into a single variable several values of possibly different kinds. For example, a variable which records details of a purchase (date, amount, description) could be built as a list of boxes:
P =: 18 12 1998 ; 1.99 ; 'baked beans' P +----------+----+-----------+ |18 12 1998|1.99|baked beans| +----------+----+-----------+
First, let's define a function t:
t =: 4 : '< (>x) g3 (>y)'t unboxes its x and y arguments, applies f, then boxes the result. (Is this a monad (in the Haskell sense)?)
Now let's define a function h:
h =: 4 : 't/\. (<"0 i.-x),(<y)'The lefthand side of this function is straightforward: insert / is an adverb that zips a verb between items of an array. For example:
+/ 1 2 3 4
10When used with suffix \., it applies the given function between successively longer suffixes of y. Or, per the documentation: "It's a loop that reports the results of each iteration." So now the question is, what kind of array is on the righthand side?
J might look intimidating, especially longer tacit functions, but breaking apart long functions can make them much less daunting. Let's break down (<"0 i.-x),(<y). , is easy: that concatenates two arrays. (<y) is easy too: it boxes up y.
Now let's look at (<"0 i.-x). i.-x will generate a descending array of integers:
i.-10
9 8 7 6 5 4 3 2 1 0Meanwhile, <"0 boxes up individual atoms of i.-x. "0 is necessary to ensure that the atoms of the array are boxed and not the entire array itself:
<"0 i.-10
┌─┬─┬─┬─┬─┬─┬─┬─┬─┬─┐
│9│8│7│6│5│4│3│2│1│0│
└─┴─┴─┴─┴─┴─┴─┴─┴─┴─┘
< i.-10
┌───────────────────┐
│9 8 7 6 5 4 3 2 1 0│
└───────────────────┘Finally, if we put the righthand side of this function together, substituting 10 for x and x_0 for y, we get:
(<"0 i.-10),(<x_0)
┌─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬────────────────────────────────────────────────────────────────────────────────┐
│9│8│7│6│5│4│3│2│1│0│1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30│
└─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴────────────────────────────────────────────────────────────────────────────────┘This sets us up to use /\. to insert t between atoms of this array, with each subsequent invocation using the newly-returned array as input to the next invocation of t.
Let's test it out! Let's attempt to get the third row, beginning with x_0:
2 h x_0
┌────────────────────────────────────────────────────────────────────────────┬──────────────────────────────────────────────────────────────────────────────┬────────────────────────────────────────────────────────────────────────────────┐
│2 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30│2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30│1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30│
└────────────────────────────────────────────────────────────────────────────┴──────────────────────────────────────────────────────────────────────────────┴────────────────────────────────────────────────────────────────────────────────┘This looks closer to what we want, but it's a bit tough to read, though, so let's use ravel ,. to make it a bit easier. Ravel will, among other things, turn an array into a one-column table:
,. 2 h x_0
┌────────────────────────────────────────────────────────────────────────────────┐
│2 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 │
├────────────────────────────────────────────────────────────────────────────────┤
│2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 │
├────────────────────────────────────────────────────────────────────────────────┤
│1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30│
└────────────────────────────────────────────────────────────────────────────────┘Although they're in reverse order, we have the first three rows of our table!
Motion to table¶
Given what we have so far, we can generate arbitrary tables, but we still need to figure out where along the diagonal 11 occurs, so we have a little more transformation to do. In the style of the APL game of life video, I'll quickly build up this function as we go, showing intermediate results along the way.
First, we unbox the results:
> ,. 2 h x_0
2 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 0 0
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30Next we reverse the order of the rows with reverse |.:
|. > ,. 2 h x_0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 0
2 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 0 0It's subtle, but there's a problem with this, and it's hinted at by the newlines the J REPL printed out with each row. If we examine the dimensionality of this table, we see something interesting:
x =: |. > ,. 2 h x_0
$ x
3 1 30This isn't actually a table, it's a three dimensional array, which would be cool if we were in Hackers or something, but this is real life, where phone booths don't spin. So we ravel it again (notice the lack of extra newlines):
,. |. > ,. 2 h x_0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 0
2 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 0 0Now we retrieve an array of the diagonal with (< 0 1) |::
(< 0 1) |: ,. |. > ,. 2 h x_0
1 3 5If we increase the left argument to h a bit it becomes clearer that this is indeed the diagonal from the image:
(< 0 1) |: ,. |. > ,. 8 h x_0
1 3 5 7 4 12 10 17 6We're finally ready to figure out where 11 occurs in this sequence! First, we'll need some breathing room in x_0. Because we don't quite know how large the table needs to be, let's just set it to something big:
x_0 =: 1+i.9999
1+((<0 1) |: ,. |. > ,. 999 h x_0) i. 11
416i. 11 will return the index of 11 in the diagonal array, and 1+ will offset it by one because the indexes in the puzzle are one-based. Just to be sure we're correct, we should test one of the given values:
1+((<0 1) |: ,. |. > ,. 999 h x_0) i. 2
75Oh right, this was about golf¶
Now for the fun part (okay, the more fun part, because we're already having fun). Much like trying to write a tweet pre-2017, we're going to need to get rid of as many characters as we can while still retaining the original meaning.
Let's work backwards. We've defined a lot of functions along the way here, but that was mostly for convenience and ease of development. Now that the program works, we can work our way down the stack and effectively inline all of the functions we created with their tacit forms. We begin with the nouns. x_0 becomes 1+i.9999:
1+((<0 1) |: ,. |. > ,. 999 h 1+i.9999) i. 11For the functions, we're going to cheat a bit. See, tacit definitions are great, but as you can imagine, it isn't always easy or straightforward to write them (at least not for me). Luckily, the J interpreter will happily create tacit forms for us!
I object to doing things that computers can do. — Olin Shivers
If you specify an explicit function definition with 13 as its type, the interpreter will return the tacit version of your function:
h
4 : 't/\. (<"0 i.-x),(<y)'
13 : 't/\. (<"0 i.-x),(<y)'
[: t/\. ([: <"0 [: i. [: - [) , [: < ]
1+((<0 1) |: ,. |. > ,. 999 ([: t/\. ([: <"0 [: i. [: - [) , [: < ]) 1+i.9999) i. 11
416We've replaced h with its tacit definition (and swaddled it in parentheses to avoid an error). Now we have to deal with t:
13 : '< (>x) g3 (>y)'
[: < ([: > [) g3 [: > ]
1+((<0 1) |: ,. |. > ,. 999 ([: ([: < ([: > [) g3 [: > ])/\. ([: <"0 [: i. [: - [) , [: < ]) 1+i.9999) i. 11
416Now g3:
g3
g1 , g2
g1
4 : '((x + (f3 x)) { y)'
13 : '((x + (f3 x)) { y)'
] {~ [ + [: f3 [
g2
4 : '(1 + x * 2) }. y'
13 : '(1 + x * 2) }. y'
] }.~ 1 + 2 * [
1+((<0 1) |: ,. |. > ,. 999 ([: ([: < ([: > [) ((] {~ [ + [: f3 [),(] }.~ 1 + 2 * [)) [: > ])/\. ([: <"0 [: i. [: - [) , [: < ]) 1+i.9999) i. 11
416Now f3. We can do this one by hand (and with some rearranging to eliminate parentheses):
f3
f2 * f1
f2
2 # 1 + i.
f1
$&_1 1&double
double
2&*
1+((<0 1) |: ,. |. > ,. 999 ([: ([: < ([: > [) ((] {~ [ + [: ($&_1 1&(*&2)*2#1+i.) [),(] }.~ 1 + 2 * [)) [: > ])/\. ([: <"0 [: i. [: - [) , [: < ]) 1+i.9999) i. 11
416Finally, we remove the unnecessary spaces:
1+((<0 1)|:,.|.>,.999([:([:<([:>[)((]{~[+[:($&_1 1&(*&2)*2#1+i.)[),(]}.~1+2*[))[:>])/\.([:<"0[:i.[:-[),[:<])1+i.9999)i.11
416Et voilà! Let's see where this clocks in character-wise:
david@curie ~
% echo -n '1+((<0 1)|:,.|.>,.999([:([:<([:>[)((]{~[+[:($&_1 1&(*&2)*2#1+i.)[),(]}.~1+2*[))[:>])/\.([:<"0[:i.[:-[),[:<])1+i.9999)i.11' | wc -m
121121 characters, 121 bytes. This could fit in a tweet! Could it be shorter? It's certainly possible. We might be able to eliminate some parentheses in spots by making better use of function composition, which could potentially go from two characters (, ) to one @. The function that handles iterating to generate new rows could potentially be shorter too. We also can't say for sure that the tacit version returned by the interpreter is the shortest possible function.
Conclusion¶
So there you have it. Jane Street's May puzzle solved in 121 utterly incomprehensible bytes. If you've found a shorter solution, I'd love to see it, and perhaps even post it here with your permission. Don't hesitate to reach out about this or anything else! You can e-mail me at david@davidfluck.com.
If you'd like to learn more about J, I'll share some helpful links in the next section.
Thanks for reading!